-
OverViewFlink/Learn Flink 2024. 3. 31. 23:26
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/learn-flink/overview/
Overview
Learn Flink: Hands-On Training # Goals and Scope of this Training # This training presents an introduction to Apache Flink that includes just enough to get you started writing scalable streaming ETL, analytics, and event-driven applications, while leaving
nightlies.apache.org
다음 공식 문서를 읽고 필요 내용을 정리, Flink 1.17 버전 기준으로 정리했습니다.
1. Stram Process
- Batch Porcessing
- bounded data stream을 처리할 때 사용
- 정해져 있는 범위의 input을 넣기 때문에 데이터를 정렬하거나 요약을 한 후에 저리할 수 있는 특징이 있음
- Streaming Processing
- unbounded data stream을 처리할 때 사용
- input이 제한되어있지 않기 때문에 계속 처리해 줘야 함
- flink에서 여러 사용자 정의 operator로 streaming dataflow를 구성할 수 있도록 함

- source는 데이터를 가져오는 역할을 하고 하나 혹은 여러개로 구성 될 수 있음
- 실시간 데이터를 가져오고 메세지 큐같은 곳이 데이터 source가 될 수 있음(ex. kafka, kinesis)
- bounded 데이터 source도 가능
- transformation은 사용자가 정의한 operator가 될 수 있음
- 하나의 transformation이 여러개의 operator로 구성 될 수 있음
- sink는 데이터를 보내는 역할을 하고 하나 혹은 여러개로 구성 될 수 있음
2. Parallel Dataflows

- flink는 parallel, distribute한 특징을 가지고 있음
- 실행시, 스트림은 하나 혹은 여러개의 스트림 partition으로 나뉘고 하나의 operator는 하나 혹은 여러개의 subtasks로 구성되어 있음
- 각각의 subtask는 독립적, 다양한 스레트에서 실행할 수 있으며 다른 기계나 컨테이너에서 실행할 수 있음
- 다른 operator는 다른 level의 parallelism에 위치 (subtasks가 같으면 같은 parallelism에 있음)
- 스트림은 2가지 방식으로 데이터를 보낼 수 있음 -> one-to-one / redistributing 패턴
- 1) One-to-one (위 그림에서 Souurce -> map으로 가는 부분)
- 2) Redistributing (위 그림에서 map -> keyBy/window, keyBy/window -> Sink로 가는 부분)
- 스트림의 파티션이 바뀌는 부분
- keyBy, broadcast, rebalance 등의 메소드로 발생 (경험상으로는 하나의 partition에 데이터가 쏠려<skew> 속도가 느려지는 걸 방지할 때 중요하게 사용되는 것으로 알고있음)
3. Timely Streaming Processing
- 스트리밍 프로세스에서는 어떠한 이벤트가 발생했는지에 대해서 주의를 기울임 (처리하는 시간에 집중하기 보다는)
- 머신 time을 기록하기 보다는 data stream의 event timestamp를 기록하는 것을 요구함
4. Stateful Streaming Processing
- flink operator는 statefule함
- 모든 이벤트의 이전 결과에 영향을 받아 현재 이벤트 처리를 진행
- flink는 state는 locally하게 접근 가능하게 구성해서 high throughput과 low-latency를 만족하도록 함
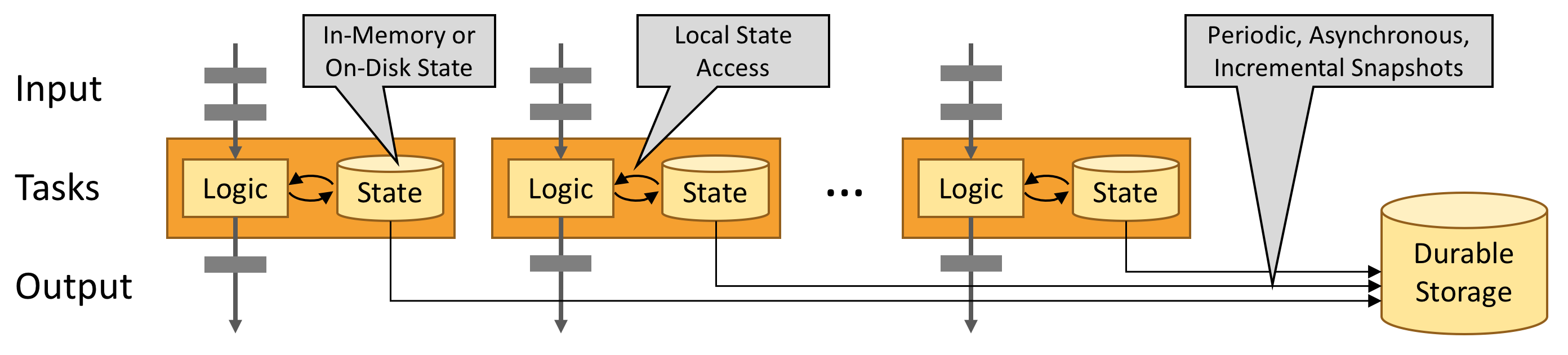
- state저장을 JVM Heap, on-disk에 저장할 것인지 설정 가능
5. Fault Tolerance Via State Snapshot
- flink는 fault-tolerance와 exactly-once 구현을 snapshot을 활용해서 구현
- snapshot
- job graph의 정보 뿐만 아니라 모든 state의 정보를 기록함
- job fail이 일어날 시 state는 복구되고 처리가 재실행됨
- 4번 Stateful Straming Processing 그림에서처럼 state snapshot은 비동기적으로 일어남
'Flink > Learn Flink' 카테고리의 다른 글
Data Pipelines & ETL (0) 2024.04.15 DataStream API Intro (0) 2024.04.07 - Batch Porcessing